characters: alphabet | points | character encodings | punctuation | accents | unicode | operators | implicit types | mulitdimensional arrays | delimiters | whitespace | control characters | keyboard keys | phonetics
tools: command line usage | prompt commands | gui | web
documentation: locations | generators | markup | mathematics | diagrams | abbreviations | html | css
code: regular expressions | file glob patterns | file names | file suffixes | grammars | indentation | syntax highlighting | logging | testing | configuration | metrics | big o notation | memory
data: normal form | idl
calculi: turing machine | untyped lambda calculus | combinatory logic | communicating sequential processes
appendix: color | dates | time zones | countries and languages | geographic coordinates
Be consistent.
ALPHABET
| A | alfa | ⋅- | N | november | -⋅ | |
| B | bravo | -⋅⋅⋅ | O | oscar | --- | |
| C | charlie | -⋅-⋅ | P | papa | ⋅--⋅ | |
| D | delta | -⋅⋅ | Q | quebec | --⋅- | |
| E | echo | ⋅ | R | romeo | ⋅-⋅ | |
| F | foxtrot | ⋅⋅-⋅ | S | sierra | ⋅⋅⋅ | |
| G | golf | --⋅ | T | tango | - | |
| H | hotel | ⋅⋅⋅⋅ | U | uniform | ⋅⋅- | |
| I | india | ⋅⋅ | V | victor | ⋅⋅⋅- | |
| J | juliett | ⋅--- | W | whiskey | ⋅-- | |
| K | kilo | -⋅- | X | xray | -⋅⋅- | |
| L | lima | ⋅-⋅⋅ | Y | yankee | -⋅-- | |
| M | mike | -- | Z | zulu | --⋅⋅ | |
POINTS
Refer to Unicode points like this: U+03BB
Refer to ASCII points like this: %x2F.
In Unicode Point notation, e.g U+03BB, the hex digit can be 4, 5, or 6 characters long. Use upper case letters for hex digits.
The notation for ASCII points derives from ABNF notation: e.g. %x2F for slash. Compare with percent encoding notation used in URLs: %2F.
CHARACTER ENCODINGS
Use UTF-8 or US-ASCII.
Treat character encoding names case-insensitively.
The iconv command line tool and the libiconv library convert data from one character encoding to another. iconv -l lists the supported character encodings.
US-ASCII
ISO8859-1
CP437
WINDOWS-1252
UTF-8
UTF-16
UTF-16BE
UTF-16LE
The three names for UTF-16 are not synonyms. If one ignores surrogate pairs, each character takes two bytes. If the most significant byte is first—i.e. has a smaller address—the encoding is big-endian (UTF-16BE), otherwise it is little-endian (UTF-16LE). Or one can specify the encoding as UTF-16 and prepend a byte-order mark (BOM: U+FEFF) to the data. Since there is no Unicode character with point U+FFFE, the receiver can determine the endianness by inspecting the first two bytes.
The IANA maintains a list of character encoding names:
http://www.iana.org/assignments/character-sets/character-sets.xhtml
The IANA list is not identical to the iconv -l list. The IANA encodings are used to specify character encodings in HTTP and HTML.
For HTTP:
Content-Type: text/html; charset=ISO-8859-1
HTML (must appear in first 1024 bytes of document):
<meta http-equiv="Content-Type" content="text/html; charset=utf-8">
HTML5 alternative:
<meta charset="utf-8">
XML:
<?xml version="1.0" encoding="ISO-8859-1"?>
To show the character encodings that Emacs recognizes:
M-x describe-variable <RET> charset-list
PUNCTUATION
Use short names for ASCII punctuation.
Use punctuation names which indicate whether the character is being used as an accent, delimiter, or standalone.
Don't use colloquial names for punctuation in writing.
| point | symbol | name | unicode name | note |
|---|---|---|---|---|
| %x21 | ! | exclamation mark | bang is a convenient spoken abbrevation | |
| %x22 | " | double quote | QUOTATION MARK | when used as delimiter |
| %x22 | " | dieresis | QUOTATION MARK | when used as accent; usage obsoleted by U+0308: COMBINING DIAERESIS |
| %x23 | # | number sign | hash is a convenient spoken abbreviation | |
| %x24 | $ | dollar sign | ||
| %x25 | % | percent sign | ||
| %x26 | & | ampersand | ||
| %x27 | ' | single quote | APOSTROPHE | when used in pairs to delimit |
| %x27 | ' | apostrophe | APOSTROPHE | when used as standalone |
| %x27 | ' | acute accent | APOSTROPHE | when used as accent; usage obsoleted by U+0301: COMBINING ACUTE ACCENT |
| %x28 %x29 |
( ) | left paren right paren |
LEFT PARENTHESIS RIGHT PARENTHESIS |
|
| %x2A | * | asterisk | star is a convenient spoken abbreviation | |
| %x2B | + | plus sign | ||
| %x2C | , | comma | ||
| %x2D | - | hyphen | HYPHEN-MINUS | when used in compound words |
| %x2D | - | minus sign | HYPHEN-MINUS | when used as operator |
| %x2E | . | period | FULL STOP | |
| %x2F | / | slash | SOLIDUS | |
| %x3A | : | colon | ||
| %x3B | ; | semicolon | ||
| %x3C | < | less-than sign | LESS-THAN SIGN | |
| %x3D | = | equals sign | ||
| %x3E | > | greater-than sign | GREATER-THAN SIGN | |
| %x3C %x3E |
< | right angle bracket left angle bracket |
LESS-THAN SIGN GREATER-THAN SIGN |
when used in pairs to delimit |
| %x3F | ? | question mark | ||
| %x40 | at sign | COMMERCIAL AT | ||
| %x5B %x5D |
[ ] | left square bracket right square bracket |
||
| %x5C | \ | backslash | REVERSE SOLIDUS | |
| %x5E | ^ | caret | CIRCUMFLEX ACCENT | when used as standalone |
| %x5E | ^ | circumflex | CIRCUMFLEX ACCENT | when used as accent; usage obsoleted by U+0302: COMBINING CIRCUMFLEX |
| %x5F | _ | underscore | LOW LINE | |
| %x60 | ` | backquote | GRAVE ACCENT | when used as delimiter |
| %x60 | ` | grave accent | GRAVE ACCENT | when used as an accent: usage obsoleted by U+0300: COMBINING GRAVE ACCENT |
| %x7B %x7D |
{ } | left brace right brace |
LEFT CURLY BRACKET RIGHT CURLY BRACKET |
|
| %x7C | | | vertical bar | VERTICAL LINE | pipe is a convenient spoken abbreviation |
| %x7E | ~ | tilde | when used as standalone and accent; usage as accent obsoleted by U+0303: COMBINING TILDE | |
The following non-ASCII punctuation characters are regarded by some as necessary to render English in a typographically correct way:
| point | symbol | name |
|---|---|---|
| U+2013 | – | en dash |
| U+2014 | — | em dash |
| U+2018 U+2019 |
‘ ’ | left single quotation mark right single quotation mark |
| U+201C U+201D |
“ ” | left double quotation mark right double quotation mark |
ACCENTS
Use the following names for accents.
Prefer NFC normalized character streams.
| accent | accented a | unicode name of accented a |
|---|---|---|
| acute | á | LATIN SMALL LETTER A WITH ACUTE |
| grave | à | LATIN SMALL LETTER A WITH GRAVE |
| circumflex | â | LATIN SMALL LETTER A WITH CIRCUMFLEX |
| dieresis | ä | LATIN SMALL LETTER A WITH DIAERESIS |
| tilde | ã | LATIN SMALL LETTER A WITH TILDE |
| caron | ǎ | LATIN SMALL LETTER A WITH CARON |
| macron | ā | LATIN SMALL LETTER AE WITH MACRON |
| breve | ă | LATIN SMALL LETTER A WITH BREVE |
| overdot | ȧ | LATIN SMALL LETTER A WITH DOT ABOVE |
| underdot | ạ | LATIN SMALL LETTER A WITH DOT BELOW |
OPERATORS
When casually expressing mathematical operations with ASCII characters, follow C usage.
When casually expressing mathematical operations in Unicode, follow Algol 60 usage.
precedence | arithmetic operators | logic operators | transcendental functions | fortran | apl | c
| algol 60 | fortran iv | dartmouth basic | apl | pascal | c | ||
|---|---|---|---|---|---|---|---|
| 1960 | 1962 | 1964 | 1967 | 1970 | 1972 | ||
| assignment | |||||||
| assignment | := | = | let | ← | := | = | |
| arithmetic | |||||||
| add | + | + | + | + | + | + | |
| unary minus | - | - | - | U+2212: − | - | - | |
| subtract | - | - | - | U+2212: − | - | - | |
| multiply | × | * | * | × | * | * | |
| divide | / | / | / | ÷ | / | / | |
| quotient | ÷ | div | / | ||||
| modulus | argument order is reversed: U+2223: ∣ |
mod | % | ||||
| power | ↑ | ** | ^ | U+22C6: ⋆ | Power() | pow() | |
| square root | sqrt() | sqrt() | sqr() | U+22C6: ⋆0.5 | Sqrt() | sqrt() | |
| comparison | |||||||
| equal | = | .eq. | = | = | = | == | |
| not equal | ≠ | .ne. | < | ≠ | /= | != | |
| less-than | < | .lt. | < | < | < | < | |
| less-than or equal | ≤ | .le. | <= | ≤ | <= | <= | |
| greater-than | .gt. | ||||||
| greater-than or equal | ≥ | .ge. | = | ≥ | >= | >= | |
| logic | |||||||
| and | ∧ | .and. | ∧ | and | && | ||
| or | ∨ | .or. | ∨ | or | @ | @ | |
| unary not | ¬ | .not. | U+223C: ∼ | not | ! | ||
| transcendental | |||||||
| natural exponential | exp() | exp() | exp() | U+22C6: ⋆ | Exp() | exp() | |
| natural logarithm | ln() | alog() | log() | U+235F: ⍟ | Ln() | log() | |
| sine | sin() | sin() | sin() | U+25CB: 1○ | Sin() | sin() | |
| cosine | cos() | cos() | cos() | U+25CB: 2○ | Cos() | cos() | |
| tangent | tan() | U+25CB: 3○ | Tan() | tan() | |||
| inverse sine | ¯1○ | ArcSin() | asin() | ||||
| inverse cosine | ¯2○ | ArcCos() | acos() | ||||
| inverse tangent | arctan() | atan() | atn() | ¯3○ | ArcTan() | atan() | |
| inverse tangent with two arguments | atan2() | ArcTan2() | atan2() | ||||
| float truncation | |||||||
| absolute value | abs() | abs() | abs() | U+2223: ∣ | Abs() | fabs() | |
| round towards zero | int() | int() | Trunc() | (int) | |||
| round to nearest | Round() | round() | |||||
| floor | entier() | U+230A: ⌊ | Floor() | floor() | |||
| ceiling | U+2308: ⌈ | Ceil() | ceil() | ||||
precedence
Use the following precedence rules to reduce the number of parens in expressions:
C operators, from highest to lowest precedence:
- function invocation and array indexing: () []
- unary operators: ! -
- multiplicative operators: * / %
- additive operators: + -
- comparison operators: = != < <= > >=
- logical operators: && ||
- assignment: =
arithmetic operators
Division on integers returns a rational number. Many languages will approximate the result with a floating point number.
Quotient is only defined on integers and returns a integer. Some languages including C use the same operator for quotient as for floating point division. We think it is a poor practice, but whatever operator is used, don't call quotient division. The defining property of division is that it is the inverse of multiplication:
(x / y) * y = x
(x * y) / y = x
The defining property of quotient is:
(m / n) * n + m % n = m
Languages vary in how they interpret m % n when m is negative and n is positive. In the case of C m % n is negative, but in Python m % n is positive. We think the Python interpretation is more mathematical because % is an additive group homomorphism that way. In Python, the result is in {{ {0, 1, ..., n-1} regardless of the sign of m.
logic operators
The original (1957) FORTRAN compiler and Dartmouth BASIC (1964) did not have the logical operators AND, OR, or NOT.
Nesting an IF statement in the TRUE branch implements AND.
Nesting an IF statement if the FALSE branch implements OR.
Reversing the TRUE and FALSE branches implements NOT.
transcendental functions
The tan, arcsin, and arccos can be computed by these identities:
(1)The arguments of the trigonometric functions and the return values of the inverse trigonometric functions are in radians. The customary ranges of the inverse trigonometric functions are:
| function | range |
|---|---|
| arcsin | −π/2 ≤ y ≤ π/2 |
| arccos | 0 ≤ y ≤ π |
| arctan | −π/2 < y < π/2 |
The inverse trigonometric functions are true inverses of the trigonometric functions when their domains are restricted to the above ranges. The arctan can be used to convert rectangular coordinates to polar coordinates, but the two argument version is better because it avoids a piecewise definition of the angle:
#include <math.h>
r = sqrt(x*x + y*y);
theta = atan2(x, y);
fortran
The original FORTRAN compiler released in 1957 supported the arithmetic operators. The original compiler and the FORTRAN IV compiler released in 1962 ran on IBM hardware that used a 48 character set. It contained the 26 upper case letters, 10 digits, space, and these 11 punctuation characters:
& . ⌑ - $ * / , % # @
The 3rd character did not make it into the ASCII character set. In Unicode it is U+2311 and has the name SQUARE LOZENGE. How the character was used is a mystery.
To support Fortran, a special version of the IBM 026 keypunch was used. I think it made these substitutions:
| standard 026 | fortran 026 |
|---|---|
| # | = |
| & | + |
| % | ( |
| ⌑ | ) |
The original FORTRAN compiler did not have comparison operators or logical operators. Instead it had a feature called the arithmetic IF which inspected a value and jumped to one of three locations depending upon whether it was less than, equal to, or greater than zero. Comparison was performed using arithmetic IF on the difference of the two values.
Fortran 90 added these comparison operators: {{== /= < <= > >=.
apl
APL calls unary operators monadic functions and binary operators dyadic functions. Unary operators are prefix and binary operators are infex. APL does not have functions with syntax like the other languages. In APL terminology, operators are functions which take a function as an argument. An example of such an operator is /, which acts like reduce. The following expression uses addition to reduce the list [1, 2, 3] and evaluates to 6:
+ / 1 2 3
True and false are 1 and 0.
Some functions can be used as monadic and dyadic functions. In addition to minus, which works like other languages, the ∣ function (U+2223) is absolute value when monadic and modulus when dyadic. ⋆ (U+22C6) is the exponential function when monadic and the power function when dyadic. The ○ function (U+25CB) is a multiple of π when monadic and a trigonometric function when dyadic, with the first argument determining which trigonometric function.
Most APL function work on arrays. The following performs elementwise addition to give 3 5 7:
1 2 3 + 2 3 4
This performs elementwise multiplication to give 2 6 12:
1 2 3 × 2 3 4
The dot product of the two vectors is sum of the elementwise multiplication, which is 20. In APL we can compute it with:
+ / 1 2 3 × 2 3 4
The above uses the reduce operator /. It also uses the fact that APL expressions are parsed from right to left.
Another way to compute the dot product is:
1 2 3 +.× 2 3 4
The . operator is called the inner product operator. It takes two dyadic functions as its arguments and returns a dyadic function.
When a scalar is added to an array, the scalar is added to each element of the array. This expression evaluates to 2 3 4:
1 + 1 2 3
Otherwise, adding arrays of different length does not work. This results in a LENGTH ERROR:
1 1 + 1 2 3
Matrices are created by reshaping an array. This APL expression
2 2 ⍴ 1 2 3 4
creates the matrix:
(4)To create a 2x2 matrix of all zeros or all ones:
2 2 ⍴ 0
2 2 ⍴ 1
To add two matrices to get a 2x2 matrix of all fives:
( 2 2 ⍴ 1 2 3 4 ) + 2 2 ⍴ 4 3 2 1
Again, APL expressions are parsed from right to left. The parens, which work like other languages, are necessary to prevent the APL interpreter from trying to add a 2x2 matrix with the array 1 2 3 4.
Matrix multiplication is performed like the dot product of arrays:
( 2 2 ⍴ 1 2 3 4 ) +.× 2 2 ⍴ 4 3 2 1
monadic minus vs high minus
prefix sum +\ (scan)
range
random (roll deal)
take / drop
concat / ravel ,
min/max (use floor ceil)
membership
decode / encode
matrix invese
general transpose
reverse / rotate
grade up / grade down
factorial / combinations
outer product
⌶ 2336 APL FUNCTIONAL SYMBOL I-BEAM
⌷ 2337 APL FUNCTIONAL SYMBOL SQUISH QUAD
⌸ 2338 APL FUNCTIONAL SYMBOL QUAD EQUAL
⌹ 2339 APL FUNCTIONAL SYMBOL QUAD DIVIDE
⌺ 233A APL FUNCTIONAL SYMBOL QUAD DIAMOND
⌻ 233B APL FUNCTIONAL SYMBOL QUAD JOT
⌼ 233C APL FUNCTIONAL SYMBOL QUAD CIRCLE
⌽ 233D APL FUNCTIONAL SYMBOL CIRCLE STILE
⌾ 233E APL FUNCTIONAL SYMBOL CIRCLE JOT
⌿ 233F APL FUNCTIONAL SYMBOL SLASH BAR
⍀ 2340 APL FUNCTIONAL SYMBOL BACKSLASH BAR
⍁ 2341 APL FUNCTIONAL SYMBOL QUAD SLASH
⍂ 2342 APL FUNCTIONAL SYMBOL QUAD BACKSLASH
⍃ 2343 APL FUNCTIONAL SYMBOL QUAD LESS-THAN
⍄ 2344 APL FUNCTIONAL SYMBOL QUAD GREATER-THAN
⍅ 2345 APL FUNCTIONAL SYMBOL LEFTWARDS VANE
⍆ 2346 APL FUNCTIONAL SYMBOL RIGHTWARDS VANE
⍇ 2347 APL FUNCTIONAL SYMBOL QUAD LEFTWARDS ARROW
⍈ 2348 APL FUNCTIONAL SYMBOL QUAD RIGHTWARDS ARROW
⍉ 2349 APL FUNCTIONAL SYMBOL CIRCLE BACKSLASH
⍊ 234A APL FUNCTIONAL SYMBOL DOWN TACK UNDERBAR
⍋ 234B APL FUNCTIONAL SYMBOL DELTA STILE
⍌ 234C APL FUNCTIONAL SYMBOL QUAD DOWN CARET
⍍ 234D APL FUNCTIONAL SYMBOL QUAD DELTA
⍎ 234E APL FUNCTIONAL SYMBOL DOWN TACK JOT
⍏ 234F APL FUNCTIONAL SYMBOL UPWARDS VANE
⍐ 2350 APL FUNCTIONAL SYMBOL QUAD UPWARDS ARROW
⍑ 2351 APL FUNCTIONAL SYMBOL UP TACK OVERBAR
⍒ 2352 APL FUNCTIONAL SYMBOL DEL STILE
⍓ 2353 APL FUNCTIONAL SYMBOL QUAD UP CARET
⍔ 2354 APL FUNCTIONAL SYMBOL QUAD DEL
⍕ 2355 APL FUNCTIONAL SYMBOL UP TACK JOT
⍖ 2356 APL FUNCTIONAL SYMBOL DOWNWARDS VANE
⍗ 2357 APL FUNCTIONAL SYMBOL QUAD DOWNWARDS ARROW
⍘ 2358 APL FUNCTIONAL SYMBOL QUOTE UNDERBAR
⍙ 2359 APL FUNCTIONAL SYMBOL DELTA UNDERBAR
⍚ 235A APL FUNCTIONAL SYMBOL DIAMOND UNDERBAR
⍛ 235B APL FUNCTIONAL SYMBOL JOT UNDERBAR
⍜ 235C APL FUNCTIONAL SYMBOL CIRCLE UNDERBAR
⍝ 235D APL FUNCTIONAL SYMBOL UP SHOE JOT
⍞ 235E APL FUNCTIONAL SYMBOL QUOTE QUAD
⍟ 235F APL FUNCTIONAL SYMBOL CIRCLE STAR
⍠ 2360 APL FUNCTIONAL SYMBOL QUAD COLON
⍡ 2361 APL FUNCTIONAL SYMBOL UP TACK DIAERESIS
⍢ 2362 APL FUNCTIONAL SYMBOL DEL DIAERESIS
⍣ 2363 APL FUNCTIONAL SYMBOL STAR DIAERESIS
⍤ 2364 APL FUNCTIONAL SYMBOL JOT DIAERESIS
⍥ 2365 APL FUNCTIONAL SYMBOL CIRCLE DIAERESIS
⍦ 2366 APL FUNCTIONAL SYMBOL DOWN SHOE STILE
⍧ 2367 APL FUNCTIONAL SYMBOL LEFT SHOE STILE
⍨ 2368 APL FUNCTIONAL SYMBOL TILDE DIAERESIS
⍩ 2369 APL FUNCTIONAL SYMBOL GREATER-THAN DIAERESIS
⍪ 236A APL FUNCTIONAL SYMBOL COMMA BAR
⍫ 236B APL FUNCTIONAL SYMBOL DEL TILDE
⍬ 236C APL FUNCTIONAL SYMBOL ZILDE
⍭ 236D APL FUNCTIONAL SYMBOL STILE TILDE
⍮ 236E APL FUNCTIONAL SYMBOL SEMICOLON UNDERBAR
⍯ 236F APL FUNCTIONAL SYMBOL QUAD NOT EQUAL
⍰ 2370 APL FUNCTIONAL SYMBOL QUAD QUESTION
⍱ 2371 APL FUNCTIONAL SYMBOL DOWN CARET TILDE
⍲ 2372 APL FUNCTIONAL SYMBOL UP CARET TILDE
⍳ 2373 APL FUNCTIONAL SYMBOL IOTA
⍴ 2374 APL FUNCTIONAL SYMBOL RHO
⍵ 2375 APL FUNCTIONAL SYMBOL OMEGA
⍶ 2376 APL FUNCTIONAL SYMBOL ALPHA UNDERBAR
⍷ 2377 APL FUNCTIONAL SYMBOL EPSILON UNDERBAR
⍸ 2378 APL FUNCTIONAL SYMBOL IOTA UNDERBAR
⍹ 2379 APL FUNCTIONAL SYMBOL OMEGA UNDERBAR
⍺ 237A APL FUNCTIONAL SYMBOL ALPHA
⎕ 2395 APL FUNCTIONAL SYMBOL QUAD
c
What about ** or ^ instead of power() and abs() instead of fabs().
Case sensitive. All other languages aren't.
The language which used ASCII characters most effectively?
triglyphs
bit operators
compound assignment
bad features: address, pointer deref, increment, decrement
IMPLICIT TYPES
By default, a Fortran compiler will allow use of undeclared variables. The type of the variable is inferred from the first letter of the name: if it is in the range I-N, the variable is an integer and is initialized to 0, otherwise it is a real and initialized to 0.0.
Fortran is case-insensitive, but some languages which are case-sensitive enforce a distinction on the case of the first letter. For example, the Ruby interpreter assumes that variables with an uppercase first letter are immutable; the Ruby interpreter emits a warning if the value in the variable is changed.
underscores
greek letters
MULTIDIMENSIONAL ARRAYS
DELIMITERS
- _ : ; . , " ' () [] {}
delimiters in file names: - _ , .
WHITESPACE
binary operator
delimiters
CONTROL CHARACTERS
Use Unix notation to refer to C0 control characters.
Don't refer to C1 control characters.
The C0 control characters were defined as part of the the ASCII standard. These include %x00 through %x1F and the delete character %x7F. The space character %x20 is an honorary control character.
The C1 control characters in the range %x80 through %x9F were defined as part of ECMA-48 in 1976, but they are little used today.
The Unicode standard does not define control characters. It leaves the ranges U+0000 through U+001F and U+007F through U+009F blank.
"Unix" notation predates Unix, since it was used in ITS operating system documentation in 1969.
| ASCII | Unix | Emacs | Microsoft | C string |
|---|---|---|---|---|
| NUL | ^ | C- | \000 | |
| SOH | ^A | C-a | CTRL+A | \001 |
| STX | ^B | C-b | CTRL+B | \002 |
| ETX | ^C | C-c | CTRL+C | \003 |
| EOT | ^D | C-d | CTRL+D | \004 |
| ENQ | ^E | C-e | CTRL+E | \005 |
| ACK | ^F | C-f | CTRL+F | \006 |
| BEL | ^G | C-g | CTRL+G | \a |
| BS | ^H | C-h | BACKSPACE (CTRL+H) | \b |
| TAB | ^I | TAB (C-i) | TAB (CTRL+I) | \t |
| LF | ^J | RET (C-j) | ENTER (CTRL+J) | \n |
| VT | ^K | C-k | CTRL+K | \v |
| FF | ^L | C-k | CTRL+L | \f |
| CR | ^M | C-m | CTRL+M | \r |
| SO | ^N | C-n | CTRL+N | \016 |
| SI | ^O | C-o | CTRL+O | \017 |
| DLE | ^P | C-p | CTRL+P | \020 |
| DC1 (XON) | ^Q | C-q | CTRL+Q | \021 |
| DC2 | ^R | C-r | CTRL+R | \022 |
| DC3 (XOFF) | ^S | C-s | CTRL+S | \023 |
| DC4 | ^T | C-t | CTRL+T | \024 |
| NAK | ^U | C-u | CTRL+U | \025 |
| SYN | ^V | C-v | CTRL+V | \026 |
| ETB | ^W | C-w | CTRL+W | \027 |
| CAN | ^X | C-x | CTRL+X | \030 |
| EM | ^Y | C-y | CTRL+Y | \031 |
| SUB | ^Z | C-z | CTRL+Z | \032 |
| ESC | ^[ | ESC (C-[) | ESC | \033 |
| FS | ^\ | C-\ | \034 | |
| GS | ^] | C-] | \035 | |
| RS | ^^ | C-^ | \036 | |
| US | ^_ | C-_ | \037 | |
| SP | SPC | SPACEBAR | ||
| DEL | ^? | DEL | DELETE | \177 |
Keyboard Keys
Modern American keyboards can produce all the ASCII characters, and all of the printing ASCII characters (except for the lowercase letters) are printed on the keys. Many keys can be designated by the ASCII character they produce.
windows keyboard

apple keyboard

apple wireless keyboard

Notation for keys which do not produce an ASCII character:
| pc name | pc short | pc alt | mac name | mac symbol | mac alt | emacs |
|---|---|---|---|---|---|---|
| Escape | Esc | Esc | ⎋ | |||
| F1 ... F16 | F1 ... F16 | F1 ... F16 | F1 ... F16 | |||
| Print Screen | Prt Scr | |||||
| Scroll Lock | ScrLk | |||||
| Pause | ||||||
| Backspace | Delete | ⌫ | <DEL | |||
| Insert | ||||||
| Home | Home | ↖ | ⌘↑ | |||
| Page Up | PgUp | Page Up | ⇞ | Fn↑ | ||
| Num Lock | ||||||
| Tab | Tab | ⇥ | <TAB> | |||
| Delete | ⌦ | |||||
| End | End | ↘ | ⌘↓ | |||
| Page Down | PgDn | Page Down | ⇟ | Fn↓ | ||
| Caps Lock | Caps Lock | ⇪ | ||||
| Enter | Return | ⏎ | <RET | |||
| Shift | Shift | Shift | ⇧ | |||
| Control | Ctrl | Control | ^ | C- | ||
| Windows Logo | CTRL+Esc | Command | ⌘ | |||
| Alt | Option | ⌥ | M- | |||
| Alt Grapheme | AltGr | CTRL+Alt | ||||
| Menu | Shift+F10 | |||||
| Left Arrow | Left Arrow | ← | ||||
| Up Arrow | Up Arrow | ↑ | ||||
| Down Arrow | Down Arrow | ↓ | ||||
| Right Arrow | Right Arrow | → | ||||
| System Request | SysRq | Alt+Prt Scr | ||||
| Power | ||||||
| Function | Fn | |||||
| Enter | ||||||
| Media Eject | ⏏ |
PHONETICS
- ipa
- american dictionary
- symbols for english, french, german, spanish
COMMAND LINE USAGE
GNU command usage uses ALLCAPS for metavariables. Uppercase letters are not used too often in the Unix environment. Flags are sometimes uppercase, so there is some potential for ambiguity.
Notation for invoking commands at a POSIX shell prompt use the following meta-characters [ ] | ( ) ... Items in brackets are optional. Items separated by pipes are alternatives. When one of the alternatives must be used they are put in parens, otherwise they are put in square brackets [ ]. The ellipsis is used to indicate an item that can be repeated.
PROMPT COMMANDS
A dollar sign $ can be used to indicate that the code is to be executed at a POSIX prompt:
$ echo foo
Use sudo to indicate a command which must be executed as root:
$ sudo apt-get install emacs
For other prompts—SQL prompts, DOS prompts, REPL prompts—use > unless there is a convention for using something else.
> SELECT count(*) FROM customers;
DOS prompt usage uses ALLCAPS for commands and lowercase for metavariables. Note that DOS is not case sensitive so the commands do not have to be typed in ALLCAPS. Parens are interpreted literally in DOS prompt usage.
SQL documentation uses ALLCAPS for literals and lowercase for metavariables. SQL is case insensitive, but there is a convention for writing reserved words in ALLCAPS. [ ] is used for optional elements and | for alternation. Braces { } are used to group alternatives when one of them must be used.
GUI
Use hierarchical menu notation to show how to do something on a GUI.
Hierarchical menu notation looks like this:
Computer | Properties | Advanced system settings | Environment Variables
The user starts by pulling down the Computer menu and selecting Properties. The user is presented with another menu in which he should see Advanced system settings. If he selects it he should see Environment Variables.
Some of the elements that the user must manipulate might not have a text title. If the GUI element has a well-known name, use that. Otherwise it must be described. Use italics or angle brackets to distinguish names and descriptions from titles.
<start menu> | Run
If it is necessary to mention what must be done with the mouse, we suggest putting the action inside pipes.
Two-finger click on an icon to bring up the context menu and select Properties:
<icon> |two-finger-click| Properties
<icon> |right-click| Properties
Double click on an icon:
<icon> |double-click|
Drag an icon to the Recycle bin:
<icon> |drag| Recycle Bin
WEB
info:
- upper left logo links to homepage
- top nav bar on all pages
- underline links in distinct color (mouseover highlighting)
- vertical scroll only (minimum width; adapting to width?)
- no scroll high-jacking
- mimimize state of page (ideally, only scroll position)
- no mazes (need for exploration)
- beware of the modern <blink> or <marquee> features
- no frames
form:
- how to make buttons look like buttons
- in place errors; ideally detect errors before submit
- partial page reloads
app:
- eliminate scrolling
- don't redefine browser key bindings
LOCATIONS
Put documentation in a standard place.
Command line tools should have usage and a man page.
Interactive tools should have online help.
A repository should have a README and a build file.
A build file should have a default task.
The public functions and methods of a library should have comments or doc strings.
Generated documentation should be HTML.
These are the standard locations for documentation:
- usage
- man page
- online help
- code: comments and doc strings
- special tools (javadoc, perldoc, ri, …)
- repository: README and build file
- public web page
usage
If a non-interactive command is invoked with invalid arguments, it should write usage to standard error and exit with a non-zero status.
It should be possible to use the {{--help}} flag to get usage. A non-interactive command which performs a destructive action when invoked with {{--help as its only argument is insidious.
See command line usage for notation.
man page
Whenever a command line tool is installed in /THE/PATH/TO/bin, the man page for the tool should be installed in /THE/PATH/TO/man/man1.
The standard sections for a man page are
- NAME
- SYNOPSIS
- DESCRIPTION
- OPTIONS
- SEE ALSO
- AUTHOR
online help
The way to access online help should always be visible, or should be displayed at start up.
The online help should list all the available functionality with the keybindings or commands used to invoke it in a concise format.
| interactive cmd | to get help |
|---|---|
| bash | help man bash |
| zsh | man builtin man zshall |
| cmd.exe | help |
| emacs | C-h b current key bindings C-h i manual |
| vim | :help index key bindings :help manual |
| nano | C-g |
| less | h |
| tmux | C-b ? |
| screen | C-a ? |
| top | ? |
| tig | h |
| psql | \? |
| mysql | \h |
| sqlite3 | .help |
| mongo | help |
| redis-cli | help <TAB |
code: comments and doc strings
Make comments one of three types: interface, implementation, or file.
An interface comment appears immediately before a top level definition such as a function, class, method, data structure, global variable, or constant. The comment describes how to use the definition.
Some languages (Lisp, Python) support doc strings, which are a strings which appear as the first statement in a function or method body. The advantage of a doc string is that it makes the documentation available at the REPL.
An implementation comment appears inside a function or method body. It can appear immediately before a statement or set off by space. An implementation comment might include a URL to a written description of the algorithm being used. Implementation comments that start with TODO or FIXME are used as reminders about incomplete or substandard implementations.
A file comment is the first comment in a file. It should be set off from a following definition by a space. A file comment might summarize the organizational principle used to decide what goes into the file.
If a directory needs a comment, put a README file in the directory.
man page:
- c
- tcl
repository: README and build file
Formats:
- web/PDF/ePub/wiki
- math (mathjax or google)
GENERATORS
Keep documentation together with the code it documents under version control.
Write a build target for generating the documentation.
- doxygen
- javadoc
- perldoc
- pydoc
- sphinx
- rdoc
MARKUP
Put long form documentation in markup.
Use a readable markup.
Use a markup which supports the following features but not much more.
- links
- anchors
- italic font weight
- bold font weight
- fixed width font: must be distinct from proportional font. Used to embed names from code in English text.
- unordered lists: must be able to nest one level and insert line breaks
- tables
-
- must be able to control line breaks
- links, anchors, font weight, fixed width font
- cells which span more than one column
-
- plain text blocks: used for code. Markup in block is not rendered.
- embedded images
- section headings (number of levels? if more than two, use outline notation to distinguish)
Fixed width font is used for source code. It can be used to set off source code which is embedded into natural language text. Embedding source code should usually be limited to identifers, keywords, and operators, and possibly short expressions. Source code consisting of one or more full statements should be set off in a block. Note that the contrast between a monospace font and a proportional font depends on the choice of fonts; use of CSS effects such as color may be advisable to increase the contrast.
Use of italics:
- foreign words and phrases (often only the first occurrence)
- key words and phrases (first occurrence)
- titles and subtitles
- to indicate emphasis in spoken speech.
- letters when used to refer to themselves
- scientific: units of measurement, genus and species
- mathematical: variables
In hand-written text, underlining is used where italics would be used in typeset text.
Boldface is normally used for headings. In HTML it is thus implied by header tags, though this can be controlled via the CSS. It can be used to make the first phrase or sentence in a paragraph to stand out.
MATHEMATICS
- history of ascii math?
- conventions for translating math variables to ascii math variables: subscripts, superscripts, both, greek letters
- mathjax
- ipython, sympy, and latex
DIAGRAMS
dot | linked list | hasse | entity-relationship | class | flowchart | state | petri net | railroad | folk architecture | euler | venn
On the Theory of Scales of Measurement Stevens 1946
Joint Committee on Standards for Graphical Presentation Brinton etal 1914
Stevens wrote a paper in 1946 in which he identified 4 ways in which numbers can be used:
- nominal: numbers are just identifiers like phone numbers
- ordinal: the natural order of the numbers is meaningful
- interval: the difference between two numbers is meaningful
- ratio: the distance of a number to zero is meaningful
A plot is a type of chart in which one can read off meaningful ordered pairs of interval or ratio numbers, in the manner of the analytic geometry of Descartes.
Diagrams are graphs (in the sense of graph theory), usually directed graphs, with information attached to the vertices and edges. Usually there are symbolic conventions which depend on the type of diagram for associating information with the vertices or edges. At times we might call the vertices nodes and the edges arrows.
One can read order pairs off of a graph, but the components are nominal—being names of vertices or nodes—and the pairs themselves represent edges or arrows.
Diagrams which document data structures:
- linked list
- hasse
- entity-relationship
- class
Diagrams which document processes:
- flowchart
- state machine
- petri net
Diagrams which document a grammar:
- railroad
Also:
- folk architecture
Set diagrams:
- euler
- venn
dot
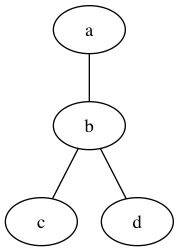
DOT is a graph description language. This is an undirected graph:
graph {
a -- b -- c;
b -- d;
}
$ brew install graphviz
$ dot -Tpng < /tmp/graph.dot > /tmp/graph.png
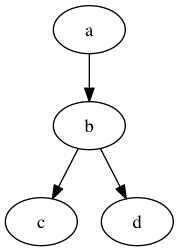
This is a directed graph:
digraph {
a -> b -> c;
b -> d;
}
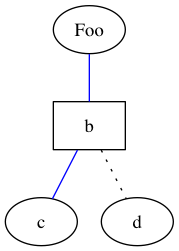
How to set attributes of the vertices and edges:
graph {
a [label="Foo"];
b [shape=box];
a -- b -- c [color=blue];
b -- d [style=dotted];
}
linked list
An instance of a record (or struct) can be represented by a box divided horizontally or vertically into its fields. If a field contains a non-pointer value, say a number or string, it is written inside the field. If the field contains a pointer, an arrow is drawn from inside the field to the edge of the record at the address of the pointer.
Showing operations on linked lists is cumbersome. One could redraw the linked list with each change in state.
digraph foo {
rankdir=LR;
node [shape=record];
edge [tailclip=false];
a [label="{ <data> 12 | <ref> }"]
b [label="{ <data> 99 | <ref> }"];
c [label="{ <data> 37 | <ref> }"];
d [shape=box];
a:ref:c -> b:data [arrowhead=vee, arrowtail=dot, dir=both];
b:ref:c -> c:data [arrowhead=vee, arrowtail=dot, dir=both];
c:ref:c -> d [arrowhead=vee, arrowtail=dot, dir=both];
}

hasse
When a graph is directed and acyclic (a DAG), we can replace the arrows with lines and use the position of the nodes to infer the direction. For example, trees are often drawn with the root nodes at the top. Also, the fields containing pointers can be omitted and each line connect the edge of a parent with the edge of a child.
Showing operations on trees is cumbersome.
A DAG defines a partially ordered set (poset). A lattice is a poset in which every pair of elements has a least upper bound (aka supremum or join or) and a greatest lower bound (aka infimum or meet). A bounded lattice has a greatest element (aka maximum, top, or ⊤) and a least element (aka minimum, bottom, or ⊥). Lattices are often drawn with Hasse diagrams.
entity-relationship
Relational data can be documented using an ER diagram. Each table is represented by a rectangle with the name of the table inside. Optionally the column names can appear below the table name separated by a line.
The graph nature of the diagram is used to show which columns can be joined with which. The cardinality of the join is represented by crows-feet notation or ISO min-max notation. Crows-feet notation can represent the minimum number as either zero or one and the max number as either one or many. ISO min-max notation uses parens and a comma: e.g (1, 1) when each row must join with exactly one row in the other table.
ER diagrams are somewhat imprecise about which column is joined with which. Often one of the columns is the primary key of the table. Naming conventions for primary keys (such as calling it id) and foreign keys such as calling it (<relationship>_<table>_id) can help. Other joins can be meaningful.
class
In a class diagram, a class is represented by a rectangle with the name of the class inside. Optionally the members of the class can be listed separated from the class name by a line.
Inheritance arrows have open triangular heads point from a subclass to a superclass.
Class members can be methods (i.e. functions) or atttributes (i.e. objects). Aggretation arrows have diamond heads and point from a class to the attribute of a class which instantiates that class. Aggregation arrows are comparable to the joins of ER diagrams. UML uses min..max notation to indicate the cardinality of the relationship.
flowchart
Flowcharts descend from the process charts used by industrial engineers since the 1920s or earlier.
Process charts often used a large variety of shapes to represent decisions or actions which were specific to an industrial process, but a generic flowchart only needs to a shape for decisions (by 1970 a diamond had become standard) and actions (by 1970 rectangles or rounded rectangles had become standard). If a flowchart can include among its actions assignment to variables, then the flowchart is Turing complete and can be used represent a computer program. Circles are sometimes used to indicate the start and end point.
Since flowcharts are often understood by people who don't otherwise program, they can be useful way to describe algorithms. Flowcharts correspond to programs with unconditional jumps (i.e. GOTO) and global variables, so they became unpopular with the rise of structured programming. In UML, flowcharts are called activity diagrams.
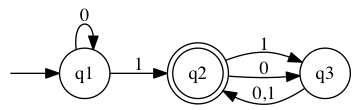
state
State diagrams model deterministic finite automata which process a string and return a binary value (the possible states of the binary value are usually called accept and reject). Accept circles are distinguished by being double circles; if the automaton is in an accept circle when the end of the input is reached, the input is accepted; otherwise it is rejected. Arrows leading out of the circle to other circles (or sometimes back to the same circle) are labelled with input values of the string.
digraph finite_state_machine {
rankdir=LR;
node [shape = point, color=white, fontcolor=white]; start;
node [shape = doublecircle, color=black, fontcolor=black]; q2;
node [shape = circle]; q1;
start -> q1;
q1 -> q1 [ label = "0" ];
q1 -> q2 [ label = "1" ];
q2 -> q3 [ label = "1" ];
q2 -> q3 [ label = "0" ];
q3 -> q2 [ label = "0,1" ];
}
petri net
Petri nets are bipartite graphs in which one set of nodes are called places and the other set of nodes are called transitions. The edges are called arcs. Each arc connects a place to a transition and has a number or weight associated with it. Places are drawn as open circles and transitions as bars. Places have zero or more tokens associated with them. The number of tokens is represented by drawing dots in the place.
If an arc point from a place to a transition, the place is called an input place of the transition. If an arc points from a transition to a place, the place is called an output place of the transition. If all the input places have more tokens in them than the weight of the corresponding arcs, then the transition is enabled and it can fire. When a transition fires, the number of tokens in the input places is decremented by the weights of the arcs, and the number of tokens in the output places is incremented by the weights of the arcs.
railroad diagram
json.org uses railroad diagrams. They first appeared in the 1972 Pascal manual by Wirth.
folk architecture
One often sees architecture diagrams in software development in which geometric shapes with names on them or clip art are connected by arrows. The geometric shapes or clip art represent components of the system being described: hosts, services, processes, or data centers. A cylinder is often used for a database or a persistent data store. The arrows usually show sharing of information, but what the arrows mean is often not called out explicitly, which is why we call them folk architecture diagrams.
euler
Euler diagrams show how two or more sets intersect and subset relations.
- disjoint
- subset
- proper subset
Don't call Euler diagrams Venn diagrams.
venn
Venn diagrams show all the ways that two or more sets can intersect. They can also show which sets elements belong to.
- converting a venn diagram to a graph: membership
- classic venn diagrams have two or three sets. More sets are quite complicated.
ABBREVIATIONS
- abbrev: abbreviate, abbreviation
- acct: account
- addr: address
- admin: administrate, administration, administrator
- agg: aggregate, aggregation
- anon: anonymous
- app: application
- Apr: April
- approx: approximate, approximation
- arg: argument
- arith: arithmetic
- assoc: association, associative
- attr: attribute
- Aug: August
- backsp: backspace
- bin: binary
- buf: buffer
- char: character
- cmd: command
- cnt: count
- col: column
- concat: concatenate, concatenation
- cond: condition, conditional
- config: configure, configuration
- conn: connection
- const: constant
- cp: copy
- ctor: constructor
- ctrl: control
- db: database
- Dec: December
- decl: declare, declaration
- decr: decrement
- def: define, definition
- del: delete
- dev: develop, development, developer
- dict: dictionary
- diff: difference
- dim: dimension
- dir: directory (not: direction)
- div: divide, division (not for: divisor or dividend)
- doc: document, documentation
- dest: destination (used with src: source)
- dtor: destructor
- elem: element
- eof: end of file
- eol: end of line
- env: environment
- eqn: equation
- err: error
- esc: escape, escaped
- eval: evaluate, evaluation
- exc: exception
- exec: execute, execution, executable
- expr: expression
- Feb: February
- fmt: format
- Fri: Friday
- func: function
- geom: geometry, geometric
- hex: hexadecimal
- id: identifier, identification
- incr: increment
- init: initialize, initialization
- int: integer (not: internal, integrate)
- iter: iterate, iterator, iteration
- Jan: January
- Jul: July
- Jun: June
- lang: language
- len: length
- lib: library
- Mar: March
- May: May
- max: maximum
- min: minimum
- mkdir: make directory
- Mon: Monday
- msg: message
- mult: multiply, multiplication, multiplicand, multiplicative
- mv: move
- namesp: namespace
- noop: no operation
- Nov: November
- num: number, numeric
- obj: object
- Oct: October
- op: operator, operation
- opt: option, optional
- param: parameter
- pct: percent
- pkg: package
- pred: predicate
- prev: previous
- proc: process (not for procedure)
- prod: product, production
- prop: property
- ptr: pointer
- ref: reference
- regex: regular expression
- repo: repository
- ret: return value
- rm: remove
- rmdir: remove directory
- rpt: report
- Sat: Saturday
- Sep: September
- seq: sequence
- src: source
- std: standard
- stderr: standard error
- stdin: standard input
- stdout: standard output
- stmt: statement
- str: string
- subst: substitute, substitution
- substr: substring
- Sun: Sunday
- tech: technical, technology
- thm: theorem
- Thu: Thursday
- tmp: temporary
- tmz: time zone
- Tue: Tuesday
- txn: transaction
- undef: undefine, undefined
- val: value
- var: variable
- vec: vector
- ver: version
- Wed: Wednesday
- whitesp: white space
HTML
An example of an HTML document:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>title</title>
<link rel="stylesheet" href="style.css">
<script src="script.js"></script>
</head>
<body>
<!-- page content -->
</body>
</html>
Some basic body tags:
- sections and headers: body div p br h1 h2 h3 h4 blockquote pre
- lists: ul ol li
- tables: table tr th td
- images: img svg
- forms: form input label
- phrase: a span em strong tt code sup sub
Some of the more import global HTML attributes:
- id
- class
- style
- data-*
CSS
A CSS reset.
Basic CSS properties:
- fonts:
- font-family
- font-weight
- font-size
- letter-spacing
- text-align
- color and display:
- color
- background-color
- display
- borders and bullets:
- border-width
- border-style
- border-color
- border-collapse
- list-style-type
- list-style-position
- location:
- position
- width
- height
- margin
- padding
- right
- left
- top
- bottom
The precedence of CSS rules is governed by the selector:
- inline style: style="font-weight:bold"
- id selector: #example
- pseudo-class: :hover
- attribute selector: [type="radio"]
- class selector: .example
- type selector: h1
- universal selector: *
If multiple rules apply and have the same type of selector, then the most recently defined rule wins.
REGULAR EXPRESSIONS
Favor ERE over BRE.
Use Python notation for named groups.
| basic | extended | perl | emacs | |
|---|---|---|---|---|
| tools | grep sed |
grep -E sed -E (Mac) sed -r (Linux) |
grep -P (Linux) python ruby |
emacs |
| alternation | none | | | | | \| |
| greedy quantification | * \{ ,\} no upper limit if second argument of \{ \} is empty |
* { } ? + |
* { } ? + |
* \{ \} ? + |
| reluctant quantification | *? { }? ?? +? |
*? ?? +? |
||
| grouping | \( \) | ( ) | ( ) shy group: (?: ) |
\( \) shy group: \(?: \) |
| character classes | [ ] [^ ] [start-end] |
[ ] [^ ] [start-end] |
[ ] [^ ] [start-end] |
[ ] [^ ] [start-end] |
| escaping in character classes | put ] first put ^ last put - first or last |
put ] first put ^ last put - first or last |
put ] first put ^ last put - first or last |
put ] first put ^ last put - first or last |
| character class abbreviations | . | . | . \d \D \s \S \w \W | . \w \W |
| anchors | ^ $ | ^ $ | ^ $ \A \b \B \Z | ^ $ \b \B |
| backmatches | \N | \N | \N | \N |
| metacharacter escapes | \., \*, \^, \$, \[, \] | \*, \^, \$, \|, \[, \], \(, \), \{, \}, \+, \? |
any non-alphanumeric with a backslash in front of it is escaped |
\. \* \+ \? \^ \$ |
Classical regexes were described in 1956 paper by Kleene on nerve nets. The paper uses ∨ for alternation where modern regexes uses the pipe: |. It also uses *, and ( ).
Ken Thompson added regular expressions to the QED editor when he ported it to CTSS in the 1960s. He also wrote the initial versions of ed and grep for Unix which introduced BRE notation.
Early Unix tools had varied notation for regular expressions. The Single Unix Specification (1997) standardized on two types of notation: basic (BRE) and extended (ERE).
debugging
A regular expression is a way of specifying a set of strings. When the substrings that matched groups in the regular expression can be recovered, a regular expression is also a way to parse a string.
matches too little
Let's call a regular expression which consists of a single literal character, anchor, character class, character class abbreviation, or group a simple expression.
If we ignore top level alternation, then a regular expression is a sequence of possibly quantified simple subexpressions.
Removing a simple subexpression from the left or right of the sequence never decreases the set of strings that a regular expression will match. That is, the new set of strings will contain the old set. If we remove all the simple subexpressions, we have an empty regular expression which matches all strings. Thus, if a regular expression is not matching an expected string, then removing subexpressions from the left or right is a way to pinpoint a simple subexpression which is not performing as expected.
If top level alternation (i.e. alternation which is not inside a group) is being used, then one can debug the regular expression by making a regular expression from the alternative that should match the string.
matches too much
- Favor anchored regular expressions.
- Favor quantification with {{+}} or {{{ } over *. Remember that a *-quantified subexpression matches the empty string.
- Favor \w, \S, or [ ] instead of .
slow
- Favor anchored regular expressions.
- Avoid nested * and +. E.g. (foo.*)*
FILE GLOB PATTERNS
| file glob character | equivalent regex |
|---|---|
| * | [^./][^/]* |
| ? | [^./] |
| ** | ([^./][^/]*/)*[^/]* |
| [ ] | [ ] |
What happens when no match
* does not match a leading period.
fish supports **, zsh and fish do not. Also Python glob.glob and Ruby Dir.glob do not.
ant fileset include exclude supports **
In zsh and fish, if a file glob pattern doesn't match anything, there is an error. In bash the file glob pattern is used as a string.
The only thing that distinguishes a file glob pattern from a string is the presence of a metacharacter. To test whether a string is also a file path, one would use the [ -e STRING ] test.
FILE NAMES
Use shell-scripting safe file names.
Many shell scripting problems can be avoided by only using these characters in file names:
a-z A-Z 0-9 _ - . ,
Also, don't start a file name with a hyphen, because some commands will interpret the file name as an option. Commands should observe the double hyphen convention for signaling the end of option processing.
Remember that file names which start with a period are skipped in some circumstances when iterating through the contents of a directory.
Hence, the regex for a safe file name which is not hidden is:
[a-zA-Z0-9,_][a-zA-Z0-9,._-]*
When files are acquired from an extraneous source, it might be desirable to scrub the file names. The simplest technique is to replace unsafe characters with an underscore, and also replace an initial period or hyphen with an underscore. This is not an injective operation and can result in two different files having the same name.
Note that some file systems are case insensitive: e.g. HFS+ used by Mac OS X.
If it is necessary to encode an array of information in a file name, do a string join with the period or comma (. or ,).
In section 5 of RFC 4648 it is recommended that Base64 encoding be used to encode arbitrary byte streams in file names with hyphen and underscore (- and _) used as the last two characters instead of plus and slash (+ and /).
There are likely limits on the length of a file name and a path name. On Linux they are:
$ getconf NAME_MAX
$ getconf PATH_MAX
FILE SUFFIXES
For source code files, here is a way to get a list of file suffixes:
$ sudo pip install Pygments
$ pygmentize -L
GRAMMARS
The Chomsky hierarchy lists 4 progressively larger classes of grammars:
- regular
- context-free grammar
- context-sensitive grammar
- recursively enumerable grammar
A regular grammar can be described by a non-recursive regular expression.
A context-free grammar can be described by a 4-tuple: (non-terminals, terminals, rules, start). The non-terminals and terminals are disjoint sets. The rules (also called production rules) are a relation between the non-terminals and expansions, which consist of zero or more non-terminals and terminals. One of the non-terminals is designated as the start symbol.
| operation | informal | ABNF | EBNF | dragon book | BNF | bison |
|---|---|---|---|---|---|---|
| specification | none | rfc5234 | iso14977 | 2nd ed., p42 | rfc733 | Bison Manual |
| rule definition | = | = | = | → | ::= | : |
| non-terminal | word | word | phrase | italic font | < ... | C identifier; conventionally lowercase |
| concatenation | juxtaposition | juxtaposition | , | juxtaposition | juxtaposition | juxtaposition |
| production rule terminator | newline | newline | ; | newline | newline | ; |
| alternation | | | / | | | | | / | | |
| alternate rule definition | =/ | |||||
| empty string | "" | "" | "" '' |
ε | <empty | %empty |
| zero or one | [ ... ] | [ ... ] | [ ... ] | none | [ ... ] *1( ... ) |
none; use alternation |
| zero or more | { ... } | 0*( ... ) | { ... } | none | *( ... ) 0*( ... ) |
none; use recursive rule |
| grouping | ( ... ) | ( ... ) | ( ... ) | none | ( ... ) | none |
| terminal string | " ... " | " ... " | " ... " ' ... ' |
bold font | some variants use double quote strings | define a token; conventionially ALL-CAPS |
| terminal character | %x2F | none | '/' | |||
| comment | ; ... | (* ... *) | none | ; ... | /* ... */ |
Also, the ABNF spec says that concatenation always means string concatenation. It is convenient to allow concatenation to also mean joining with whitespace. This prevents low level token analysis details from cluttering the grammar.
rulelist = 1*( rule / (*c-wsp c-nl) )
rule = rulename defined-as elements c-nl
; continues if next line starts
; with white space
rulename = ALPHA *(ALPHA / DIGIT / "-")
defined-as = *c-wsp ("=" / "=/") *c-wsp
; basic rules definition and
; incremental alternatives
elements = alternation *c-wsp
c-wsp = WSP / (c-nl WSP)
c-nl = comment / CRLF
; comment or newline
comment = ";" *(WSP / VCHAR) CRLF
alternation = concatenation
*(*c-wsp "/" *c-wsp concatenation)
concatenation = repetition *(1*c-wsp repetition)
repetition = [repeat] element
repeat = 1*DIGIT / (*DIGIT "*" *DIGIT)
element = rulename / group / option /
char-val / num-val / prose-val
group = "(" *c-wsp alternation *c-wsp ")"
option = "[" *c-wsp alternation *c-wsp "]"
char-val = DQUOTE *(%x20-21 / %x23-7E) DQUOTE
; quoted string of SP and VCHAR
; without DQUOTE
num-val = "%" (bin-val / dec-val / hex-val)
bin-val = "b" 1*BIT
[ 1*("." 1*BIT) / ("-" 1*BIT) ]
; series of concatenated bit values
; or single ONEOF range
dec-val = "d" 1*DIGIT
[ 1*("." 1*DIGIT) / ("-" 1*DIGIT) ]
hex-val = "x" 1*HEXDIG
[ 1*("." 1*HEXDIG) / ("-" 1*HEXDIG) ]
prose-val = "<" *(%x20-3D / %x3F-7E) ">"
; bracketed string of SP and VCHAR
; without angles
; prose description, to be used as
; last resort
ALPHA = %x41-5A / %x61-7A ; A-Z / a-z
BIT = "0" / "1"
CHAR = %x01-7F
; any 7-bit US-ASCII character,
; excluding NUL
CR = %x0D
; carriage return
CRLF = CR LF
; Internet standard newline
CTL = %x00-1F / %x7F
; controls
DIGIT = %x30-39
; 0-9
DQUOTE = %x22
; " (Double Quote)
HEXDIG = DIGIT / "A" / "B" / "C" / "D" / "E" / "F"
HTAB = %x09
; horizontal tab
LF = %x0A
; linefeed
LWSP = *(WSP / CRLF WSP)
; Use of this linear-white-space rule
; permits lines containing only white
; space that are no longer legal in
; mail headers and have caused
; interoperability problems in other
; contexts.
; Do not use when defining mail
; headers and use with caution in
; other contexts.
OCTET = %x00-FF
; 8 bits of data
SP = %x20
VCHAR = %x21-7E
; visible (printing) characters
WSP = SP / HTAB
; white space
bison:
bison converts a grammar into C code. The grammar conventionally goes into a file with a .y suffix. Bison creates a file with a .c suffix that contains a function named yyparse:
$ bison -o foo.c foo.y
The above command also creates the file foo.h which contains the tokens, described below.
yyparse returns 0 if the input conforms to the grammar, and 1 if it does not.
yyparse does not process the input directly. It expects a function yylex to exist. flex can be used to generate a yylex function. yyparse calls yylex to get the next token in the stream. It returns the token type, which is identified by an integer. It puts the token string in the global variable yytext.
parsers:
ambiguous grammars.
left-recursive grammars.
LL(k) and top down.
LR(k) and bottom up. shift and reduce.
LALR
INDENTATION
lisp
We present two ways to indent Lisp source code.
The first is nesting level indentation. The depth of the indentation indicates how deep the element is in the parse tree. Because Lisp source code shows the parse tree consistently and faithfully with parens, the depth of indentation is also the net number of left parens—where left paren is +1 and right paren is -1—one would traverse on going from the element to the beginning of the statement. Parens inside strings don't count. Two spaces are used for each level of indentation.
Example 1. The 2nd argument of mapcar is a list. It is nested one level deep:
(mapcar (lambda (x) (* x x))
'(1 2 3))
Example 2. The body of the lambda expression is two levels deep. The list is nsted one level deep:
(mapcar (lambda (x)
(* x x))
'(1 2 3))
The second method is aligned argument indentation. It can be used when the line break occurs after the first argument in an S-expression. The argument after the line break is left-aligned with the first argument of the S-expression.
Example 3:
(mapcar (lambda (x) (* x x))
'(1 2 3))
The choice of whether to use nesting level or aligned argument indentation is at the discretion of the programmer. Also, line breaks can be inserted after the head of the S-expression or after any of its arguments at the discretion of the programmer.
One note. One sees example where a S-expression is indented by nested level indentation, and an argument contained in the S-expression is indented by aligned argument indentation. Examples which work the other way around are rare and ambigous. Should the nested level element count parens to containing element which has aligned argument indentation and indent from there, or should the nested level element count all the way to the top of the statement and indent from the start of the line?
emacs-lisp-mode uses nested level indentation with two spaces by default. When emacs-lisp-mode uses nl or aa and how to override...
Splitting long strings in lisp.
A final note. Do not put right parens on a line by themselves.
Incorrect Example:
(mapcar (lambda (x) (* x x))
'(1 2 3)
)
smalltalk
n = 0
ifTrue: [
msg value: 'no hits' ]
ifFalse: [
n = 1
ifTrue: [
msg value: '1 hit' ]
ifFalse: [
msg value: n printString, ' hits' ]]
sql
SQL is case insensitive. It is conventional to put keywords in ALL-CAPS. Here is the list of PostgreSQL keywords. Note that some, but not all, of the keywords are reserved.
Some people put built-in functions in ALL-CAPS and user-defined functions in lowercase. However, this requires that one memorize the list of built-in functions to use the correct case. We recommend putting all functions in lower case. Function names in invocations can be recognized by the parens that immediately follow. Parens are used in other situations: subqueries, grouping in expressions, or CAST expressions. Note that CAST looks superficially like a function call, but the arguments are separated by an AS keyword, not a comma. Parens which do not surround the arguments of a function invocation should be separated from the preceding element by whitespace.
A SQL SELECT statement can have these clauses: SELECT, FROM, JOIN, WHERE, GROUP BY, HAVING, ORDER BY, LIMIT, OFFSET. The SELECT is the only required clause and must come first. If a SELECT statement is not put on a single line, then each clause of the SELECT statement should have a line break in front of it and be aligned with the SELECT clause:
SELECT *
FROM customers
WHERE name = 'John Smith';
- JOIN ... ON ...
- JOIN ... ON ... AND ...
- subqueries (optional AS)
- columns
- where
- common table expressions
INSERT INTO table1
VALUES ('one', 'two', 'three');
INSERT INTO table1 (col1, col2, col3)
VALUES ('one', 'two', 'three');
INSERT INTO table1
VALUES (
'one',
'two',
'three'
);
INSERT INTO table1 (
col1,
col2,
col3
)
VALUES (
'one',
'two',
'three'
);
And UPDATE statement has an UPDATE, SET, and often a WHERE clause. When not all on the same line, these three clauses are aligned:
UPDATE table1
SET col1 = 'one', col2 = 'two'
WHERE col3 = 'three';
UPDATE table1
SET
col1 = 'one',
col2 = 'two'
WHERE
col3 = 'three';
A DELETE statement normally has two clauses, DELETE FROM and WHERE. They can go on the same line, or the WHERE can be aligned under the DELETE FROM:
DELETE FROM table1
WHERE col3 = 'three';
DELETE FROM table1
WHERE
col3 = 'three';
c
kernighan & ritchie | allman | stroustrup | java | gnu | other topics
indent [options] OLD_FILE [NEW_FILE]
indent -st [options] < OLD_FILE > NEW_FILE
# INDENTATION
-iNUM: set indentation to NUM spaces (default 8)
-ut, -nut: use tabs (default), spaces for indentation
# LINES:
trailing whitespace is removed
-lNUM: set max line length to NUM (default 78)
-ciNUM: indent of continuation line (but -lp controls parens)
# BLANK LINES
-sob, -nsob: rm optional blank lines (default no)
-bacc, -nbacc: one blank line around #ifdef #endif block (default no)
-bad, -nbad: blank line after block of declarations (default no)
-bap, -nbap: blank line after procedure body (default no)
-bbb, -nbbb: blank line before block comment (default no)
# PARENS
-lp, -nlp: line up inside parens to opening paren (default), according to indent level
# EXPRESSIONS
no options, but whitespace inside parens is trimmed and whitespace is placed around binary operators
# DECLARATIONS:
-diNUM: left justify global variable names and struct names (default: 16)
-dj, -ndj: left justify (default) variable names in declarations
# PROCEDURES
-psl, -npsl: procedure name in column 1 (default)
-fbs, -nfbs: opening brace on next line (default), following declaration
-pcs, -npcs: space between function name and paren, no space (default)
-bc, -nbc: put a newline after each comma, don't (default) /* also for structs */
# IF STATEMENTS
enforces one space between "if" and following left paren "("
-br, -bl: compound stmts (such as if) in K&R (default), Allman style
-ce, -nce: cuddled else (default), not cuddled else
-ei, -nei: left justify "if else" with preceding "if" (default)
# SWITCH STATEMENTS:
-cliNUM: how much to indent case to containg switch (default 0);
# COMMENTS
-dNUM: indent level of block comment: (default 0)
-sc, -nsc: asterisks on left edge of comment
-cNUM: column trailing comments for code start on (default 33)
-cdNUM: column trailing comments for declaration start on (default 33)
-fc1, -nfc1:
-fcb, -nfcb:
Unfortunately, there is not a well-established standard for how to use braces in C, C++, and Java. The most commonly used styles differ on whether (and when) opening braces are put alone on a line by themselves, or following the element which determines the block type. They also differ in whether they use the "cuddled else" which is an else on the same line as the closing brace of the previous block.
One way to evaluate standards is by measuring the complexity of code when writing tools which check that source adheres to the standard. If the formatting tool is simple, the description of the standard will be short and the standard will be easy to describe to new developers. By this criterion, Allman, which always puts the opening brace on a new line, is superior to K&R, which only puts the opening brace on a new line when defining functions.
Another way to evaluate standards is by the compactness of conforming code. Vertical space in particular is precious.
Aligning comparable elements
Kernighan & Ritchie
Also used by the Linux Kernel, which mandates tabs for indentation and tab stops set every 8 characters.
int main(int argc, char **argv)
{
if (argc > 3) {
printf("more than three args\n");
} else {
printf("three or fewer args\n");
}
int i = argc;
while (i > 0) {
printf("processing arg %d\n", i);
--i;
}
}
Allman
int main(int argc, char **argv)
{
if (argc > 3)
{
printf("more than three args\n");
}
else
{
printf("three or fewer args\n");
}
int i = argc;
while (i > 0)
{
printf("processing arg %d\n", i);
--i;
}
}
Stroustrup
A variant of K&R which avoids the cuddled else.
class IntHolder {
public:
int n;
IntHolder(int i): n(i) { }
};
int main(int argc, char **argv)
{
if (argc > 3) {
printf("more than three args\n");
}
else {
printf("three or fewer args\n");
}
int i = argc;
while (i > 0) {
printf("processing arg %d\n", i);
--i;
}
}
Java
int main(int argc, char **argv) {
if (argc > 3) {
printf("more than three args\n");
} else {
printf("three or fewer args\n");
}
int i = argc;
while (i > 0) {
printf("processing arg %d\n", i);
--i;
}
}
GNU
int
main(int argc, char **argv)
{
if (argc > 3)
{
printf("more than three args\n");
}
else
{
printf("three or fewer args\n");
}
int i = argc;
while (i > 0)
{
printf("processing arg %d\n", i);
--i;
}
}
Other Topics
Goto labels and switch cases are left-aligned with the braces of the containing block:
switch (n) {
case 0:
printf("none\n");
1:
printf("one\n");
default:
printf("multiple\n");
}
In C++, public: and private: declarations inside a class block are left-aligned with the braces of the block.
Preprocessor directives are not indented at all:
int main(int argc, char **argv) {
#ifdef LINUX
printf("running on Linux\n");
#endif
printf("The number of args is %d\n", argc);
}
When declaring variables to be pointers, the asterisks must be in between the type pointed at and the name of the variable. Whitespace can be inserted anywhere between or around the asterisks:
int **p1;
int** p2;
int ** p3;
int * * p4;
Some people put asterisks adjacent to the type pointed at, reasoning that they are part of the the type of the variable. However, given the way the C parser works, we recommend putting the asterisks adjacent to the variable name:
/* makes the type of i1 clear: */
int **p1, i1;
/* deceptive: i2 is not a pointer: */
int** p2, i2;
Another issue is whether braces can or must be omitted when a block consists of a single statement.
/* how C parser resolves dangling else: */
if (val1)
if (val2)
printf("val1 and val2\n");
else
printf("val1 and not val2\n");
/* deceptive indentation: */
if (val1)
if (val2)
printf("val1 and val2\n");
else
printf("indented like not val1, but actually val1 and not val2\n");
Tabs
Indentation size
Inserting blank lines.
Making line oriented edits safe (leading comma, but better if language supports trailing comma), cuddled else.
SYNTAX HIGHLIGHTING
Syntax highlighting can be turned on or off in Vim with the commands :syntax enable and :syntax off.
In Emacs, one toggles highlighting with M-x font-lock-mode.
Syntax highlighting assigns text to a highlight group in Vim or a face in Emacs.
The names of the faces are supposed to be suggestive of the text that will be highlighted, but what actually gets assigned to each face is at the discretion of the person who implemented the mode. Some of the face names might not mean anything in the context of the language whose source is being highlighted.
| vim highlight group | emacs face | X11 color | rgb | |
|---|---|---|---|---|
| comment | comment | font-lock-comment-face | ##828282|gray51## | ##828282|#828282## |
| variable | identifier | font-lock-variable-name-face | chocolate | #D2691E |
| string | string | font-lock-string-face | firebrick | #B22222 |
| keyword | statement | font-lock-keyword-face | purple | #800080 |
| preprocessor directive | preproc | font-lock-preprocessor-face | ##8470FF|lightslateblue## | ##8470FF|#8470FF## |
| function name | function | font-lock-function-face | mediumblue | #0000CD |
| constant | constant | font-lock-constant-face | olivedrab | #6B8E23 |
| type | type | font-lock-type-face | darkgreen | #006400 |
| default | normal | default | black | #000000 |
| vim highlight group | emacs face | X1l color foreground | rgb foreground | X11 color background | rgb background | |
|---|---|---|---|---|---|---|
| cursor | cursor | |||||
| selected area | region | |||||
| syntax error | Error | font-lock-warning-face |
It is instructive to compare faces—and highlight groups—with the classes of CSS and HTML. Whereas an HTML element can belong to zero or more classes, a character in a document belongs to exactly one face. Faces can inherit attributes from other faces, however.
In Vim, a user can set an attribute—in this case the foreground color—with this command:
:hi Comment ctermfg=darkgray
The equivalent in Emacs:
(custom-set-faces
'(font-lock-comment-face ((t (:foreground "gray51")))))
LOGGING
Log formats recognized by Splunk
OpenVMS System Messages
Log4j User's Guide
Write errors to a separate stream from standard output.
Write each message to the error stream on a single line.
Use a logging library for consistent and parsable error stream messages.
It should be easy to use awk to summarize or filter an error stream.
Use Log4j severity levels.
Early Fortran compilers used READ, WRITE, and PRINT statements for I/O. The first argument of these commands was an integer called the unit; it indicated the device to be used. By the time of Fortran 77, 5 became associated with the keyboard and 6 became associated with the screen. In addition, modern Fortran programs will use unit 0 for error messages.
Unix and C use integers for file descriptors. The shell, when launching a program, will set up file descriptor 0 for input and file descriptors 1 and 2 for output. These are called standard input, standard output, and standard error, respectively.
The reason for two output streams is that non-fatal error messages in the output may ruin it for further processing. Also, having output may sometimes be taken as a sign of success; of course it is better to use the exit status of the program to detect failure.
If a program fails, it should cite bad input which the user can correct or the location in the code where the error condition was detected as a debugging aid for the developer. These are the primary use cases for the standard error stream.
To make error streams easy to parse and monitor, one should put each error message on a single line. Error messages may arise from different parts of the program that are unaware of each other, or the error output of multiple processes may be collected into a single file. To avoid having messages broken up, the error stream should not be buffered, or should be flushed after each message. Also, error messages shouldn't be too long.
Some standard components for an error message:
- severity level
- timestamp
- hostname
- program name
- process id
- file and line number
- source code version
- message
In the interest of consistency, one should use a library function, so that the developer need only specify the severity level and the message.
The timestamp should be human-readable, and not a Unix epoch timestamp. An ISO 8601 format is recommended for easy sorting. The lack of spaces in an ISO 8601 format makes it easier to parse out from the other fields.
VMS system messages used these severity levels:
| S | success |
| I | info |
| W | warning |
| E | error |
| F | fatal |
These remain good severity levels today, though modern systems may omit the "S: success" level. Log4j has 6 levels, and writes them out like this in all-caps:
- TRACE
- DEBUG
- INFO
- WARN
- ERROR
- FATAL
What are the numeric values associated with these?
They are different in Log4J 2.0
The hostname is useful when logs are shipped and merged.
The program name could easily be in the log file name, but it is useful to put in the message when logs are shipped and merged. The program name can be difficult for a logging library to extract programatically. The first command line argument often contains a path to the executable, but the executable might just be the interpreter for the language the application is written in. The path can be absolute or relative, and it can be confused by symbolic links. If obtained from a path, the dirname portion of the path should be removed. A program name should not have hyphens. The program name should be distinct from all other applications.
The source code version also requires effort to get. Keyword expansion is a feature from older version control systems which can still be enabled in Git and Mercurial, but most prefer not to use it because expansions might occur in incorrect places by accident.
A safer alternative is to write the current source code version to a file as part of a build or deployment process. Use git rev-parse to get the current commit identifier andgit show to get more information about the current commit:
$ git rev-parse HEAD
$ git show HEAD
Equivalent Mercurial commands:
$ hg id .
$ hg log -r .
All standard components in the list above can be ensured to not contain spaces except for the message. Hence spaces are a reasonable separator if the message is put last. Putting the severity level first is a common practice.
The logging library should check the message for newlines, carriage returns, and tabs and replace them with spaces.
It is often desirable to put stack traces in logs, but newlines are necessary to display stack traces nicely. JSON is probably the best way to cram a stack trace into a log message.
Web server logs have some standard formats. The NCSA common log format is :
127.0.0.1 user-identifier frank [10/Oct/2000:13:55:36 -0700] "GET /apache_pb.gif HTTP/1.0" 200 2326
The fields are:
- IP address of client
- The RFC 1413 identify of the client (archaic and usually unavailable?)
- The HTTP authentication user name
- The timestamp in the format illustrated
- The first line of the HTTP request (also called the request line)
- The status code that was sent to the client
- The number of bytes sent to the client.
Hyphens are used to indicate unavailable information.
The Apache combined log format adds two fields:
127.0.0.1 - frank [10/Oct/2000:13:55:36 -0700] "GET /apache_pb.gif HTTP/1.0" 200 2326 "http://www.example.com/start.html" "Mozilla/4.08 [en] (Win98; I ;Nav)"
The additional fields are:
- The HTTP_REFERER
- The HTTP_USER_AGENT
Both of these fields are double quoted, as the request line field from common log format. Backslash escapes \" are used to put double quote characters in the string. \t \n escape sequences for tabs and newlines may also be used.
The logging format recommended by Splunk:
key1=value1, key2=value2, key3=value3 . . .
The commas are optional. The key names must not have spaces, and values must be double quoted if they contain whitespace. The same escaping conventions as used in Apache logs are used here.
JSON is also a reasonable option for logs. Write the log messages out as JSON objects, one per line.
The Bunyan logging library has standard fields:
- hostname:
- level: an integer which maps to (old) Log4J severity level:
- 60: FATAL
- 50: ERROR
- 40: WARN
- 30: INFO
- 20: DEBUG
- 10: TRACE.
- msg:
- pid:
- src: file and line number info
- time: ISO 8601 string
- v: is this the bunyan log format version number.
logrotate can be used to rotate, compress, remove, and mail logs. Rotating means copying the current log to different file on the same file system with a date such as YYYY-MM-DD for daily rotation in the path. The copytruncate open can be used with applications that keep a log file descriptor open. logrotate is run from a crontab as root, usually daily. It takes a configuration file as an argument; the customary location is /etc/logrotate.conf. Often this will load application specific configuration files in /etc/logrotate.d.
where are the logs
syslog
TESTING
An example of TAP output sometimes used by unit tests:
1..48
ok 1 - call foo
not ok 2 - call bar
...
ok 48 - call baz
CONFIGURATION
Don't put code in config files.
Should the data go in a configuration file?
- syntax errors in a configuration file are easier to diagnose, especially for nonprogrammers
- getting data out of source code can reduce false hits when grepping
- data can be accessed by different languages
- data can be changed without recompiling
- configuration data can be kept out of version control
- configuration data can be be private to a user or an installation
- configuration files don't contain code, hence more secure
On Unix, system configuration files are found in /etc, and a user's personal config files are in dot files in the home directory.
If the top level directory of a repository has Unix style directory names, i.e. bin, lib, src, then consider using etc for configuration files.
INI
No mechanism for including new lines in values. White space is trimmed from properties and values.
[section]
property1 = value
; comment
property2 = another value
A convention for partitioning the key namespace:
[db]
mysql.user = root
mysql.password = xyz123
mysql.host = localhost
mysql.port = 3306
Windows Registry
INI files were used by DOS, but Windows 3.1 and Windows NT introduced a hierarchical key-value store called the Registry for system and application configuration information.
Each value in the registry has a type and an ACL. The Windows API provides library functions which applications can use to manipulate the registry. A user with Administrator privilege can inspect and edit the registry with the regedit command.
| type | description |
|---|---|
| REG_NONE | no value |
| REG_DWORD | unsigned 32-bit integer |
| REG_QWORD | unisigned 64-bit integer |
| REG_SZ | null terminated string |
| REG_EXPAND_SZ | null terminated string with environment variables |
| REG_MULTI_SZ | a list of strings; each string is null terminated and the list is terminated with an extra null |
| REG_BINARY | binary data |
| REG_LINK | a reference to another key |
| root key | content | link | |
|---|---|---|---|
| HKCU | HKEY_CURRENT_USER | currently logged-in user info | HKU\SID |
| HKU | HKEY_USERS | user info by account | |
| HKCR | HKEY_CLASSES_ROOT | file association and COM object info | merged view of KHLM\SOFTWARE\Classes and HKU\SID\Classes |
| HKLM | HKEY_LOCAL_MACHINE | system info | |
| HKCC | HKEY_CURRENT_CONFIG | hardware profile info | HKLM\SYSTEM\CurrentControlSet\Hardware Profiles\Current |
| HKPD | HKEY_PERFORMANCE_DATA | performance info |
JSON
How to check JSON for syntax errors and how to print it with indentation:
$ echo '{foo: "bar"}' | python -mjson.tool
Expecting property name: line 1 column 2 (char 1)
$ echo '{"foo": "bar"}' | python -mjson.tool
{
"foo": "bar"
}
python -mjson.tool also prints the keys of objects in sorted order, which makes it possible to diff the output.
YAML
All valid JSON is valid YAML. In addtion YAML has these features:
- comments
# FIXME: not actual value
"performance": 0.0
- unquoted keys and values
msg: lorem ipsum
- single quote strings
msg: 'don''t say "no"'
- document delimiters
---
start: 12
end: 15
---
start: 14
end: 37
- non-inline sequences
- Larry
- Mo
- Curly
# json equivalent:
["Larry", "Mo", "Curly"]
- non-inline key-value objects
---
gold: 3
silver: 5
bronze: 2
---
# json equivalent
{"gold": 3, "silver": 5, "bronze": 2}
- references
a: &id1 foo bar baz
b: bar foo quux
# set c to "foo bar baz"
c: *id1
d: wumpus wombat foo
- block scalars
long_str: |
Four score and twenty years
ago, the end of this string
is determined by indentation
short_str: lorem ipsum
- folded scalars
long_str: >
Like previous example
except that new lines are
converted to spaces
short_str: lorem ipsum
- explicit types
a: !!float 123
b: !!str 123
c: !!str Yes
- base64 scalars
picture: !!binary |
R0lGODlhDAAMAIQAAP//9/X
17unp5WZmZgAAAOfn515eXv
Pz7Y6OjuDg4J+fn5OTk6enp
56enmleECcgggoBADs=mZmE
Technical notes on YAML:
- character encoding
- special characters (at beginning of, inside) strings
- whitespace only for indentation, no tabs
- references must be a complete node
- tags and directives
One strategy for verifying the syntax of foo.yml is to convert it to JSON:
$ ruby -e 'require "yaml"; require "json"; puts YAML.load_file("foo.yml").to_json'
XML
Checking whether a document is well-formed XML; pretty-printing an XML document with indentation:
$ echo '<foo>bar</fu>' > /tmp/foo.xml
$ xmllint --format /tmp/foo.xml
/tmp/foo.xml:1: parser error : Opening and ending tag mismatch: foo line 1 and fu
<foo>bar</fu>
^
$ echo '<foo><bar>baz</bar><bar>quux</bar></foo>' > /tmp/foo.xml
$ xmllint --format /tmp/foo.xml
<?xml version="1.0"?>
<foo>
<bar>baz</bar>
<bar>quux</bar>
</foo>
schemas and valid documents
namespaces
METRICS
source lines of code (SLOC)
A distinction is sometimes made between physical SLOC, which is the line count of the source code, and logical SLOC, which excludes blank lines and comments.
An example of how to get logical SLOC for source code which uses # style comments:
awk '!/^[ \t]*$/ && !/^[ \t]*#/ { cnt += 1} END {print cnt}' foo.py
cyclomatic complexity
To calculate cyclomatic complexity, one produces the control flow graph for a program. This is a directed graph in which an edge connects each instruction to an instruction that can be executed next. In the original formulation by McCabe in 1976, there was a path from each exit instruction back to the start instruction. The CC measure was then E - N + P, where E is the number of edges, N the number of nodes, and P the number of strongly connected components. If there is a single start point and all exit instructions are connected to it, then P is 1. Then E - N + 1 is the first Betti number of the directed graph, and it is the number of distinct cycles in the graph.
abc metric
Applying the ABC Metric to C, C++, and Java (pdf) 1997
The ABC metric is a measure of assignments, branches, and conditions:
(5)- add one to A for each assignment, compound assignment, increment, or decrement:
= *= /= %= += <<= >>= &= |= ^= ++ --
- add one to B for each function call and each goto with a target label at a deeper nesting level than the goto.
- add one to C for following relational operators, the following keywords used in if and switch statements, and the ? operator of the conditional expression. Also add one to C for any if statement condition that does not use a relational operator (the so-called unary conditional expression):
== != <= >= < >
else case default
?
Big O Notation
| f(n) ∈ O(g(n)) | g is an asymptotic upper bound of f | ∃k>0 ∃n₀ ∀n>n₀ f(n) ≤ k⋅g(n) |
| f(n) ∈ Ω(g(n)) | g is an asymptotic lower bound of f | ∃k>0 ∃n₀ ∀n>n₀ f(n) ≥ k⋅g(n) |
| f(n) ∈ Θ(g(n)) | g is an asymptotic upper and lower bound of f | ∃k₁>0 ∃k₂>0 ∃n₀ ∀n>n₀ k₁⋅g(n) ≤ f(n) ≤ k₂⋅g(n) |
MEMORY
c
Many C types can have different sizes on different architectures. The sizeof macro can be used to get the size of any type on the current architecture. The offsetof macro can be used to get the position of a struct field in a struct.
The sizeof macro is sufficient for determining memory use on the heap. Remember, however, that malloc does not make a system call for each allocation, but keeps a pool of memory from which memory can be allocated for the client.
On Linux, the size of the heap is controlled by the system calls brk and sbrk. brk takes an address as an argument which is the end of the heap. It can be used to increase or decrease the size of the heap. sbrk takes a number of bytes as an argument and increases the heap size by that amount. sbrk(0) can be used to find the location of the end of the heap, which is the first addressable location outside of the heap.
On Mac OS X, malloc uses mmap instead of brk and sbrk to manage the heap.
The Windows API includes the function HeapAlloc. It can manage multiple heaps.
function stack size; threads
program size to process size
java
| type | overhead in bytes | notes |
|---|---|---|
| byte | 1 | |
| short | 2 | |
| int | 4 | |
| long | 8 | |
| char | 2 | |
| float | 4 | |
| double | 8 | |
| array | 24 | |
| object | 16 | total size multiple of 8 bytes |
| inner object | 24 | |
| reference | 8 | |
| string | 64 | each character is 2 bytes |
NORMAL FORM
A relation is a set of tuples, all with the same number of attributes.
A domain is a set of values.
A relation schema is a tuple of domains.
A relation is said to conform to a relation schema if the tuples in the relation are the same length as the relation schema, and if for each tuple in the relation, the n-th attribute belongs to the n-th domain of the relation schema.
A schema is a tuple of relation schemas.
A tuple of relations is said to conform to a schema if the n-th relation conforms to the n-th relation schema.
A candidate key is a subset of the attributes of a relation which can be used to uniquely identify the tuples.
A non-prime attribute is an attribute which is not a candidate key.
An attribute is functionally dependent on another attribute if for all relations which conform to a relation schema, there is a function which maps the second (independent) attribute to the first (dependent) attribute.
A tuple of relations with a schema is in first normal form if the domain of each attribute contains only atomic values, and the value of each attribute contains only a single value from that domain.
A tuple of relations with a schema is in second normal form if they are in first normal form and no non-prime attribute is functionally dependent on a proper subset of any candidate key.
A tuple of relations with a schema is in third normal form if they are in second normal form and if no non-prime attribute is functionally dependent on another non-prime attribute.
IDL
| omg idl | protobuf | thrift | |
|---|---|---|---|
| boolean | boolean | bool | bool |
| integer | 2, 4, and 8 bytes: short long long long |
variable length: int32 int64 sint32 sint64 4 and 8 bytes: sfixed32 sfixed64 |
i16 i32 i64 |
| unsigned integer | unsigned short unsigned long unsigned long long |
variable length: uint32 uint64 4 and 8 bytes: fixed32 fixed64 |
none |
| float | float double |
float double |
double |
| utf-8 string | wstring | string | string |
| bytes | sequence<octet | bytes | binary |
| namespace | module dom { }; |
package dom; | namespace * dom |
| import | include "foo.thrift" | ||
| comment | // comment /* comment another comment */ |
// comment | // comment /* comment another comment */ |
| struct | struct Foo { long errorCode, wstring message } |
message Foo { required int32 errorCode = 1; optional string message = 2; } |
struct Foo { 1: i32 errorCode, 2: optional string message } |
| array | sequence<long> vals | repeated int32 vals | list<i32> vals |
| default value for field | |||
| enum | enum Color { red RED = 1, BLUE = 2, GREEN = 3 } |
enum color { red = 1, blue, green } |
omg idl
http://www.omg.org/orbrev/drafts/3_idlsyn.pdf
http://www.w3.org/TR/DOM-Level-3-Core/idl/dom.idl
protobuf
https://developers.google.com/protocol-buffers/docs/overview
$ cat foo.proto
package foo;
message Foo {
required int32 id = 1;
required string name = 2;
}
$ mkdir foo
$ protoc --cpp_out=foo foo.proto
thrift
https://thrift.apache.org/docs/idl
$ cat foo.thrift
namespace * foo
struct Foo {
1: i32 id,
2: string name
}
$ thrift --gen cpp foo.thrift
TURING MACHINE
UNTYPED LAMBDA CALCULUS
Traditionally, a function was defined using an equation:
(6)A function can be defined in a piecewise manner using multiple functions:
(7)In the nineteenth century there was disagreement whether piecewise-defined functions were functions. They could be used to introduce pathological situations such as function which is not differentiable at the origin. These disagreements went away with the introduction of set theory. Functions were defined as relations with the following constraint:
(8)The f(x) notation gives the function being defined a name, but there is also anonymous notation:
(9)The lambda calculus notation is
(10)However, in its simplest form lambda calculus does not have operators for addition or exponentiation. The only operations are abstraction (i.e. expressing an anonymous function):
(λx.y)
and application (i.e. invoking a function on arguments). Here x is the function and y is the argument:
(xy)
When writing complicated lambda expressions, parens are often omitted. They can be restored with the following rules:
MNPQ = (((MN)P)Q)
λx.PQ = (λx.(PQ))
and
(11)Functions of two variables are rewritten as a function which returns a function:
(12)This technique, called currying, means that a lambda calculus which only considers functions of one variable is fully general.
The variable name which immediately follows the λ in a lambda function is the name of the argument. Occurrences of that variable in the body of the lambda function are said to be bound. Two lambda functions which are the same except for the name of the bound variable are said to be alpha equivalent. Changing the name of a bound variable is an alpha conversion. There are some restrictions on when this can be done without change the alpha equivalence class of the function, however. The new name cannot already occur in the function body as an unbound variable, for example.
- beta reduction
- eta conversion
- formal definition: variables, abstraction symbols λ and ., parens
- church booleans
- church numerals
- church pairs
- recursion
- fixed points
COMBINATORY LOGIC
(Ix) = x
((K x) y) = x
(S x y z) = (x z (y z))
I := λx.x
K := λx.λy.x
S := λx.λy.λz.x z (y z)
B := λx.λy.λz.x (y z)
C := λx.λy.λz.x z y
W := λx.λy.x y y
U := λx.x x
ω := λx.x x
Ω := ω ω
Y := λg.(λx.g (x x)) (λx.g (x x))
COMMUNICATING SEQUENTIAL PROCESSES
Communicating Sequential Processes
- ALL-CAPS words: processes
- lowercase words: events
- lowercase single letters: event variables
- A, B, C: sets of events
- X, Y, Z: process variables
αFOO = {foo, bar} i.e the alphabet of process FOO
(x → P): process which accepts event x then acts like process P.
(y → (x → P)): process which accepts y, then x, then acts like process P.
STOPαP: process with alphabet of P which never accepts an event.
A recursive definition of a process:
CLOCK = (tick → CLOCK ): a process which accepts the tick event endlessly.
VMS = (coin → (choc → VMS)): a process which accepts coin followed by choc event endlessly.
If A is an alphabet and F(X) is an expression containing X, then we can write the solutions of X = F(X) where αX = A as:
μX: A ⋅ F(X)
A process that will accept x and behave like P, or accept y and behave like Q:
(x → P | y → Q )
COLOR
Denote colors with a number sign followed by six hex digits, e.g. #ff0000.
Use X11 color names.
Ways to refer to the color red in CSS:
element { color: red }
element { color: #f00 }
element { color: #ff0000 }
element { color: rgb(255,0,0) }
element { color: rgb(100%, 0%, 0%) }
element { color: hsl(0, 100%, 50%) }
/* 50% translucent */
element { color: rgba(255, 0, 0, 0.5) }
element { color: hsla(0, 100%, 50%, 0.5) }
The first technique refers to the color by name. The web supports the 700 or so pre-defined X windows colors. On an Ubuntu system the colors and their RGB values can be found in this file:
- /usr/share/X11/rgb.txt
In Vim, one can show some of the supported colors with:
:runtime syntax/colortest.vim
In Emacs, one can get the list of colors with:
M-x list-colors-display
The next four techniques specify the color by RGB (red-green-blue) value. There is up to a byte of data for each color. The colors mix in an additive way, so that #ffffff is white. By contrast, when one mixes paint, the colors mix in a subtractive way.
In the HSL model, the hue represents a point on the color spectrum. 0% is red, 33.3% is green, 66.7% is blue, and 100% is red again. To see the colors clearly, we set the S to 100% and L to 50%.
A lightness of 0% is black and a lightness of 100% is white. A lightness of 50% is a bright color when S is 100% and gray when S is 0%. In terms of RGB values, the formulas for L and S are:
(14)When alpha is used, 100% is completely opaque and 0% is completely transparent.
DATES
Use ISO 8601 formats for dates, time of day, combined dates and time of day, durations, and intervals.
According to the ISO 8601 standard, a date specifies a day in the Gregorian calendar and a time specifies a time of day. The ISO 8601 also has recommended formats for dates and combined dates and times:
| date | YYYY-MM-DD |
| combined date and time | YYYY-MM-DDThh:mm:ss |
| combined date and time in UTC | YYYY-MM-DDThh:mm:ss+00:00 |
In the above, YYYY is the year. It must be at least 4 digits, but more than four digits can be used to represent dates in the future. The Gregorian calendar was not in use before 1582. The proleptic Gregorian calendar is an extension of the Gregorian calendar to dates before 1582. To represent years in the past, ISO 8601 years use - or optional + prefixes instead of the conventional BCE/CE or (BC/AD) suffixes. Also, the year 1 BCE is denoted +0000 and the year 2 BCE is denoted -0001.
MM is the month of the year. It is always two digits and in the range: 01, 02, ..., 12.
DD is the day of the month. It is always two digits and in the range: 01, 02, ..., 31. Some months have 28 days (February in non-leap years), 29 days (February in leap years), or 30 days (September, April, June, and November). Leap years are years evenly divisible by 4, but not by 100 unless also divisible by 400.
hh is the 24 hour of the day. It is always two digits in the range: 00, 01, ..., 23. When the UTC offset is specified, days always have 24 hours. When a time zone uses day light savings time, the local time may have days with 23 hours or 25 hours. In the US in Spring (currently the 2nd Sunday in March) the 02 hour is skipped, and the Fall (currently the 1st Sunday in November) the 02 hour is repeated. One must use UTC offsets to distinguish the two hours.
mm is the minute of the hour. It is always two digits in the range: 00, 01, ..., 59. All hours have 60 minutes.
ss is the second of the minute. It is always two digits in the range: 00, 01, ..., 60. Most minutes have 60 seconds, but 25 leap seconds have been inserted between 1972 and 2012. Leap seconds are always added to last minute of June 30th or the last minute of December 31st. Negative leap seconds?
ISO dates and times are big-endian and fixed-width. Thus, lexical sort can be used to sort ISO dates and times, assuming the collation order of the digits 0, 1, ..., 9 is correct.
In ISO 8601 terminology, a duration describes how long an occurrence lasted, whereas a time interval describes both when and how long an occurrence lasted.
As an example of ISO 8601 notation, P2Y3M4DT5H6M7S is a period of 2 years, 3 months, 4 days, 5 hours, 6 minutes, and 7 seconds. P1M is one month, but PT1M is one minute. Leading zeros are not required in a duration, nor is there an upper limit on the size of the digits. The ISO 8601 standard does not specify the length in days of a month or a year when used in a duration.
Time intervals can be specified in three ways using a solidus:
- {{<start>}}/{{<duration>
- {{<start>}}/{{<end>
- {{<duration>}}/{{<end>
{{<start>}} and {{<end>}} are combined ISO 8601 dates and times. {{<duration> is an ISO 8601 duration.
ordinal dates
ISO 8601 week dates
TIME ZONES
Denote time zones by CONTINENT/IDENTIFYING_CITY.
Denote UTC offsets by UTC±HH:MM.
A time zone is a region in which official clocks have historically been set to the same time.
The authoritative source of information about time zones is the tz database—also known as the IANA time zone database or Olson database—which uses a start time of 13 December 1901. The date is the earliest that can be represented when a Unix epoch is stored in a 32-bit signed integer. On a Unix system the tz database is stored in the /usr/share/zoneinfo directory.
Time zones names usually have a contintent/identifying_city format: e.g. America/Los_Angeles. Abbreviations such as PST and PDT can be used to refer to time zones, but they are properly abbreviations for the UTC offsets: i.e. UTC-08:00 and UTC-07:00 respectively. Also note that these abbreviations may be ambiguous: PST can stand for Pacific Standard Time or Philippine Standard Time.
COUNTRIES AND LANGUAGES
ISO 3166-1 provides a list of 2 letter codes for countries. The list used to be distributed with the tz database in /usr/share/zoneinfo. If there isn't a copy there, one can download the list from:
http://www.ietf.org/timezones/data/iso3166.tab
ISO 639-1 and ISO 639-2 provide lists of 2 letter and 3 letter codes for countries. The codes can be downloaded from:
http://www.loc.gov/standards/iso639-2/ISO-639-2_utf-8.txt
IETF language tags, which are described in rfc5646, are used to specify locales. On a Unix system the locale is determined by the value of the LANG environment variable, which is expected to contain an IETF language tag. The format of an IETF language tag is
<lang>_<COUNTRY>
where {{<lang>}} is usually a 2 letter language code in lowercase, and {{<country> is a two letter country code in all-caps.
GEOGRAPHIC COORDINATES
Eiffel tower: +48.8577+002.295/
Statue of Liberty: +40.6894-074.0447/